 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoad Damage Detection
Road damage detection is the process of identifying and categorizing different types of road damage using deep learning techniques.
Papers and Code
Intelligent Road Condition Monitoring using 3D In-Air SONAR Sensing
Mar 30, 2026In this paper, we investigate the capabilities of in-air 3D SONAR sensors for the monitoring of road surface conditions. Concretely, we consider two applications: Road material classification and Road damage detection and classification. While such tasks can be performed with other sensor modalities, such as camera sensors and LiDAR sensors, these sensor modalities tend to fail in harsh sensing conditions, such as heavy rain, smoke or fog. By using a sensing modality that is robust to such interference, we enable the creation of opportunistic sensing applications, where vehicles performing other tasks (garbage collection, mail delivery, etc.) can also be used to monitor the condition of the road. For these tasks, we use a single dataset, in which different types of damages are annotated, with labels including the material of the road surface. In the material classification task, we differentiate between three different road materials: Asphalt, Concrete and Element roads. In the damage detection and classification task, we determine if there is damage, and what type of damage (independent of material type), without localizing the damage. We are succesful in determining the road surface type from SONAR sensor data, with F1 scores approaching 90% on the test set, but find that for the detection of damages performace lags, with F1 score around 75%. From this, we conclude that SONAR sensing is a promising modality to include in opportunistic sensing-based pavement management systems, but that further research is needed to reach the desired accuracy.
StructDamage:A Large Scale Unified Crack and Surface Defect Dataset for Robust Structural Damage Detection
Mar 11, 2026Automated detection and classification of structural cracks and surface defects is a critical challenge in civil engineering, infrastructure maintenance, and heritage preservation. Recent advances in Computer Vision (CV) and Deep Learning (DL) have significantly improved automatic crack detection. However, these methods rely heavily on large, diverse, and carefully curated datasets that include various crack types across different surface materials. Many existing public crack datasets lack geographic diversity, surface types, scale, and labeling consistency, making it challenging for trained algorithms to generalize effectively in real world conditions. We provide a novel dataset, StructDamage, a curated collection of approximately 78,093 images spanning nine surface types: walls, tile, stone, road, pavement, deck, concrete, and brick. The dataset was constructed by systematically aggregating, harmonizing, and reannotating images from 32 publicly available datasets covering concrete structures, asphalt pavements, masonry walls, bridges, and historic buildings. All images are organized in a folder level classification hierarchy suitable for training Convolutional Neural Networks (CNNs) and Vision Transformers. To highlight the practical value of the dataset, we present baseline classification results using fifteen DL architectures from six model families, with twelve achieving macro F1-scores over 0.96. The best performing model DenseNet201 achieves 98.62% accuracy. The proposed dataset provides a comprehensive and versatile resource suitable for classification tasks. With thorough documentation and a standard structure, it is designed to promote reproducible research and support the development and fair evaluation of robust crack damage detection approaches.
Reliable Deep Learning for Small-Scale Classifications: Experiments on Real-World Image Datasets from Bangladesh
Jan 17, 2026Convolutional neural networks (CNNs) have achieved state-of-the-art performance in image recognition tasks but often involve complex architectures that may overfit on small datasets. In this study, we evaluate a compact CNN across five publicly available, real-world image datasets from Bangladesh, including urban encroachment, vehicle detection, road damage, and agricultural crops. The network demonstrates high classification accuracy, efficient convergence, and low computational overhead. Quantitative metrics and saliency analyses indicate that the model effectively captures discriminative features and generalizes robustly across diverse scenarios, highlighting the suitability of streamlined CNN architectures for small-class image classification tasks.
Comparative Analysis of Custom CNN Architectures versus Pre-trained Models and Transfer Learning: A Study on Five Bangladesh Datasets
Jan 07, 2026This study presents a comprehensive comparative analysis of custom-built Convolutional Neural Networks (CNNs) against popular pre-trained architectures (ResNet-18 and VGG-16) using both feature extraction and transfer learning approaches. We evaluated these models across five diverse image classification datasets from Bangladesh: Footpath Vision, Auto Rickshaw Detection, Mango Image Classification, Paddy Variety Recognition, and Road Damage Detection. Our experimental results demonstrate that transfer learning with fine-tuning consistently outperforms both custom CNNs built from scratch and feature extraction methods, achieving accuracy improvements ranging from 3% to 76% across different datasets. Notably, ResNet-18 with fine-tuning achieved perfect 100% accuracy on the Road Damage BD dataset. While custom CNNs offer advantages in model size (3.4M parameters vs. 11-134M for pre-trained models) and training efficiency on simpler tasks, pre-trained models with transfer learning provide superior performance, particularly on complex classification tasks with limited training data. This research provides practical insights for practitioners in selecting appropriate deep learning approaches based on dataset characteristics, computational resources, and performance requirements.
Evaluation of Convolutional Neural Network For Image Classification with Agricultural and Urban Datasets
Jan 04, 2026This paper presents the development and evaluation of a custom Convolutional Neural Network (CustomCNN) created to study how architectural design choices affect multi-domain image classification tasks. The network uses residual connections, Squeeze-and-Excitation attention mechanisms, progressive channel scaling, and Kaiming initialization to improve its ability to represent data and speed up training. The model is trained and tested on five publicly available datasets: unauthorized vehicle detection, footpath encroachment detection, polygon-annotated road damage and manhole detection, MangoImageBD and PaddyVarietyBD. A comparison with popular CNN architectures shows that the CustomCNN delivers competitive performance while remaining efficient in computation. The results underscore the importance of thoughtful architectural design for real-world Smart City and agricultural imaging applications.
Self-Supervised Visual Prompting for Cross-Domain Road Damage Detection
Nov 16, 2025



The deployment of automated pavement defect detection is often hindered by poor cross-domain generalization. Supervised detectors achieve strong in-domain accuracy but require costly re-annotation for new environments, while standard self-supervised methods capture generic features and remain vulnerable to domain shift. We propose \ours, a self-supervised framework that \emph{visually probes} target domains without labels. \ours introduces a Self-supervised Prompt Enhancement Module (SPEM), which derives defect-aware prompts from unlabeled target data to guide a frozen ViT backbone, and a Domain-Aware Prompt Alignment (DAPA) objective, which aligns prompt-conditioned source and target representations. Experiments on four challenging benchmarks show that \ours consistently outperforms strong supervised, self-supervised, and adaptation baselines, achieving robust zero-shot transfer, improved resilience to domain variations, and high data efficiency in few-shot adaptation. These results highlight self-supervised prompting as a practical direction for building scalable and adaptive visual inspection systems. Source code is publicly available: https://github.com/xixiaouab/PROBE/tree/main
A Benchmark Dataset for Spatially Aligned Road Damage Assessment in Small Uncrewed Aerial Systems Disaster Imagery
Dec 13, 2025This paper presents the largest known benchmark dataset for road damage assessment and road alignment, and provides 18 baseline models trained on the CRASAR-U-DRIODs dataset's post-disaster small uncrewed aerial systems (sUAS) imagery from 10 federally declared disasters, addressing three challenges within prior post-disaster road damage assessment datasets. While prior disaster road damage assessment datasets exist, there is no current state of practice, as prior public datasets have either been small-scale or reliant on low-resolution imagery insufficient for detecting phenomena of interest to emergency managers. Further, while machine learning (ML) systems have been developed for this task previously, none are known to have been operationally validated. These limitations are overcome in this work through the labeling of 657.25km of roads according to a 10-class labeling schema, followed by training and deploying ML models during the operational response to Hurricanes Debby and Helene in 2024. Motivated by observed road line misalignment in practice, 9,184 road line adjustments were provided for spatial alignment of a priori road lines, as it was found that when the 18 baseline models are deployed against real-world misaligned road lines, model performance degraded on average by 5.596\% Macro IoU. If spatial alignment is not considered, approximately 8\% (11km) of adverse conditions on road lines will be labeled incorrectly, with approximately 9\% (59km) of road lines misaligned off the actual road. These dynamics are gaps that should be addressed by the ML, CV, and robotics communities to enable more effective and informed decision-making during disasters.
Joint Training of Image Generator and Detector for Road Defect Detection
Sep 03, 2025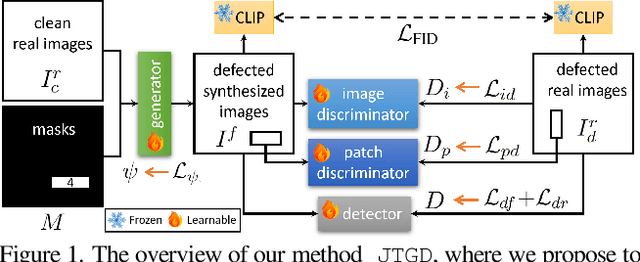

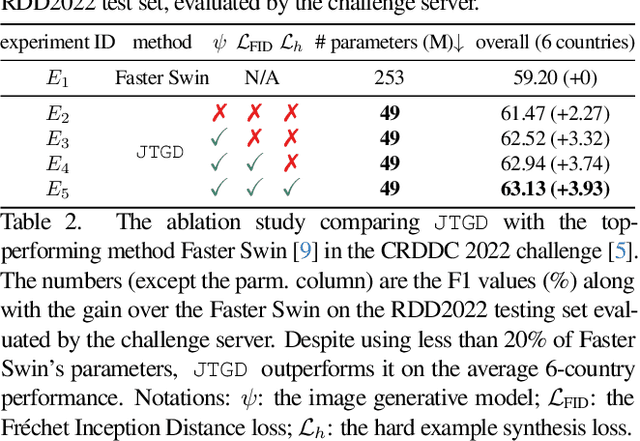
Road defect detection is important for road authorities to reduce the vehicle damage caused by road defects. Considering the practical scenarios where the defect detectors are typically deployed on edge devices with limited memory and computational resource, we aim at performing road defect detection without using ensemble-based methods or test-time augmentation (TTA). To this end, we propose to Jointly Train the image Generator and Detector for road defect detection (dubbed as JTGD). We design the dual discriminators for the generative model to enforce both the synthesized defect patches and overall images to look plausible. The synthesized image quality is improved by our proposed CLIP-based Fr\'echet Inception Distance loss. The generative model in JTGD is trained jointly with the detector to encourage the generative model to synthesize harder examples for the detector. Since harder synthesized images of better quality caused by the aforesaid design are used in the data augmentation, JTGD outperforms the state-of-the-art method in the RDD2022 road defect detection benchmark across various countries under the condition of no ensemble and TTA. JTGD only uses less than 20% of the number of parameters compared with the competing baseline, which makes it more suitable for deployment on edge devices in practice.
AI and Remote Sensing for Resilient and Sustainable Built Environments: A Review of Current Methods, Open Data and Future Directions
Jul 02, 2025Critical infrastructure, such as transport networks, underpins economic growth by enabling mobility and trade. However, ageing assets, climate change impacts (e.g., extreme weather, rising sea levels), and hybrid threats ranging from natural disasters to cyber attacks and conflicts pose growing risks to their resilience and functionality. This review paper explores how emerging digital technologies, specifically Artificial Intelligence (AI), can enhance damage assessment and monitoring of transport infrastructure. A systematic literature review examines existing AI models and datasets for assessing damage in roads, bridges, and other critical infrastructure impacted by natural disasters. Special focus is given to the unique challenges and opportunities associated with bridge damage detection due to their structural complexity and critical role in connectivity. The integration of SAR (Synthetic Aperture Radar) data with AI models is also discussed, with the review revealing a critical research gap: a scarcity of studies applying AI models to SAR data for comprehensive bridge damage assessment. Therefore, this review aims to identify the research gaps and provide foundations for AI-driven solutions for assessing and monitoring critical transport infrastructures.
Intelligent Road Anomaly Detection with Real-time Notification System for Enhanced Road Safety
May 13, 2025This study aims to improve transportation safety, especially traffic safety. Road damage anomalies such as potholes and cracks have emerged as a significant and recurring cause for accidents. To tackle this problem and improve road safety, a comprehensive system has been developed to detect potholes, cracks (e.g. alligator, transverse, longitudinal), classify their sizes, and transmit this data to the cloud for appropriate action by authorities. The system also broadcasts warning signals to nearby vehicles warning them if a severe anomaly is detected on the road. Moreover, the system can count road anomalies in real-time. It is emulated through the utilization of Raspberry Pi, a camera module, deep learning model, laptop, and cloud service. Deploying this innovative solution aims to proactively enhance road safety by notifying relevant authorities and drivers about the presence of potholes and cracks to take actions, thereby mitigating potential accidents arising from this prevalent road hazard leading to safer road conditions for the whole community.